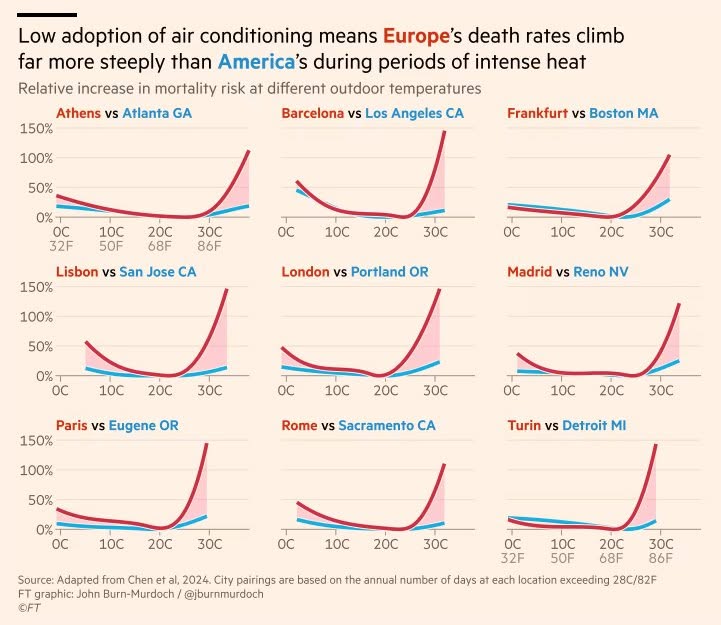
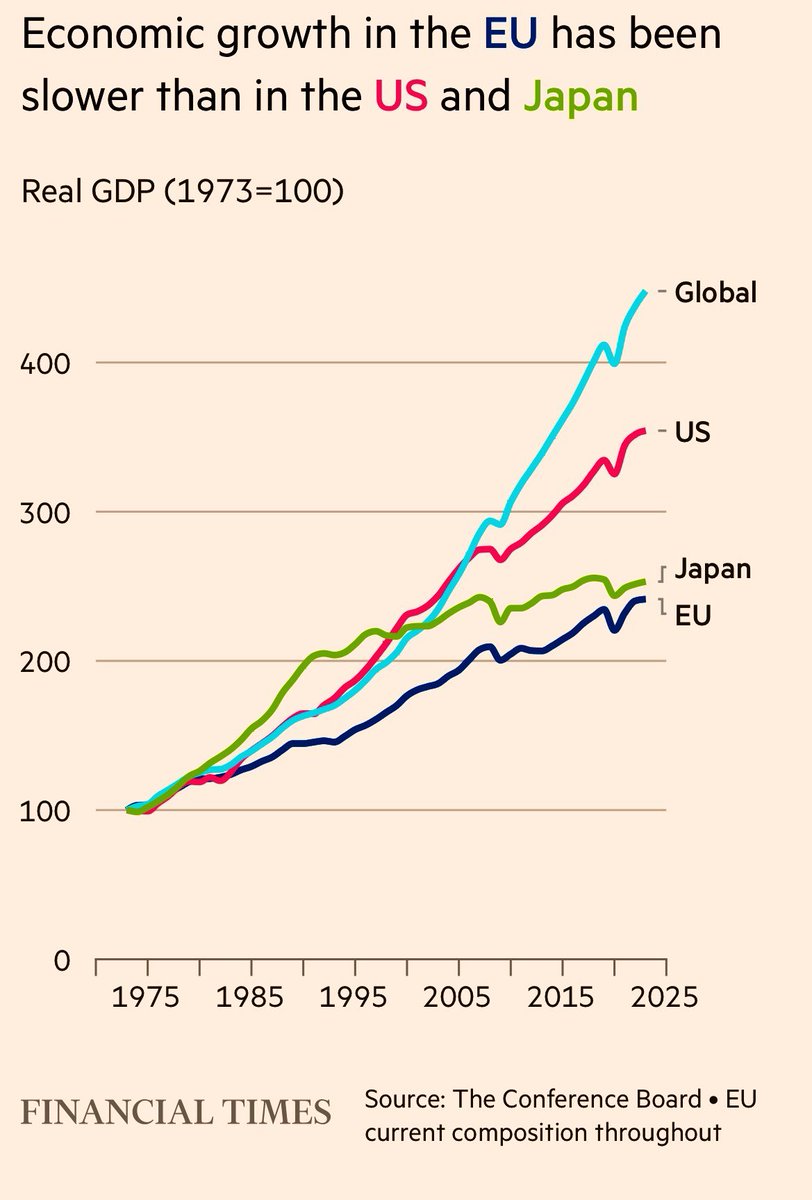
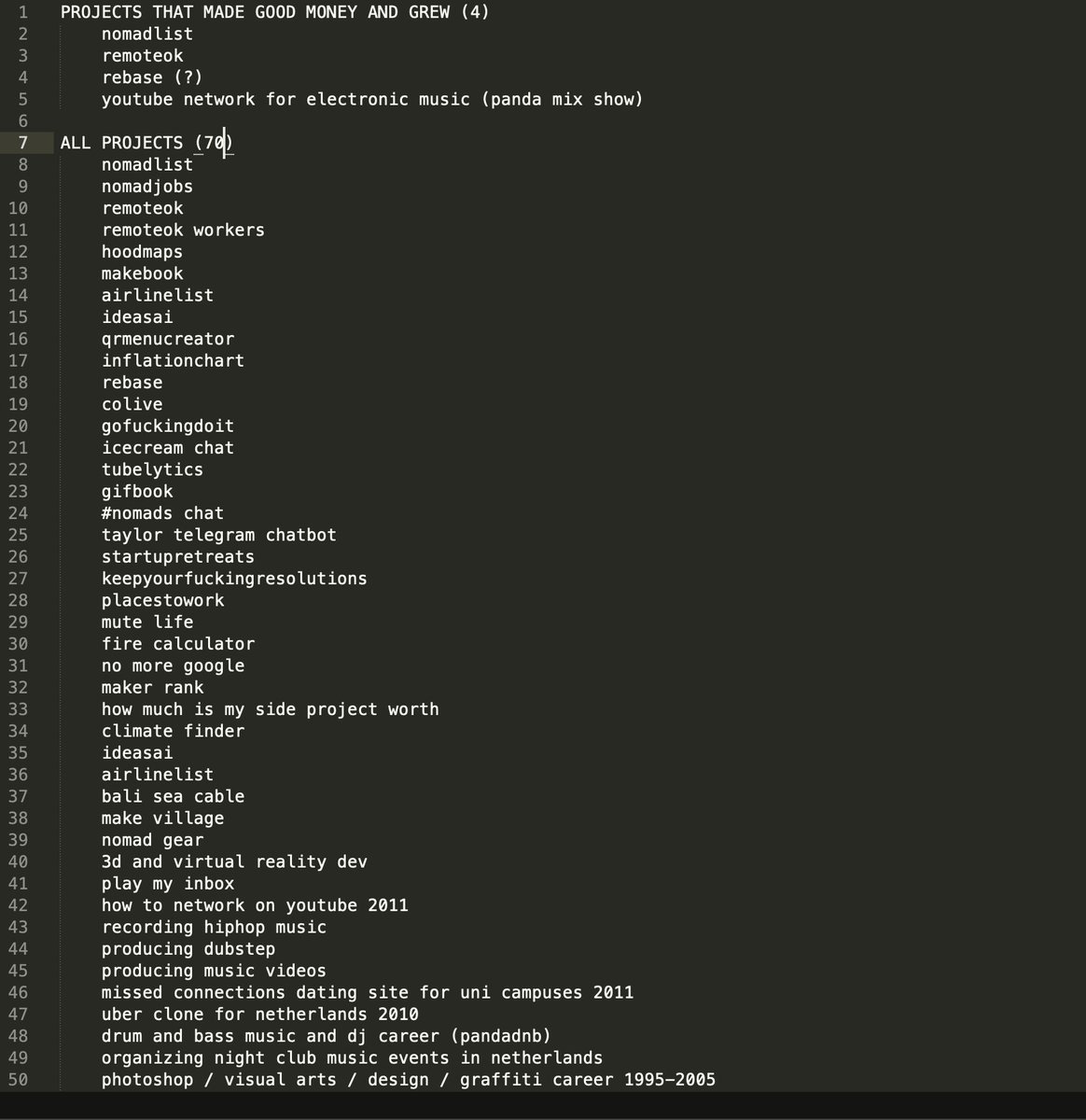
How to backup your Linode or Digital Ocean VPS to Amazon S3
This year I learnt how to build, run and maintain my own server. It now runs on Linode and runs all websites for my projects including all 12 startups in 12 months. It runs nginx and manages to survive 1,000+ users per second from Hacker News and Product Hunt out-of-the-box fine. I still think that’s a miracle since I’m a supernoob and I set it up myself and it’s just 4GB ram Linode server. With my startup Nomad List now getting increasingly popular, my server is now also becoming increasingly important for me now. If it dies, I’m completely f*d. So I want to start doing regular backups. Today I’m going to find out how to do that easily and cheap. And share the results with you backups built-in which is awesome. It’s just a little per month extra. But storing your server and backups at the same hosting company is a single point of failure. Therefore, I want to store another backup somewhere else.
So today I’m going to make an automatic offsite backup program. It can also be used for people with Digital Ocean VPS server or any other VPS really. Mine runs Ubuntu which is kind of standard now.
Solution

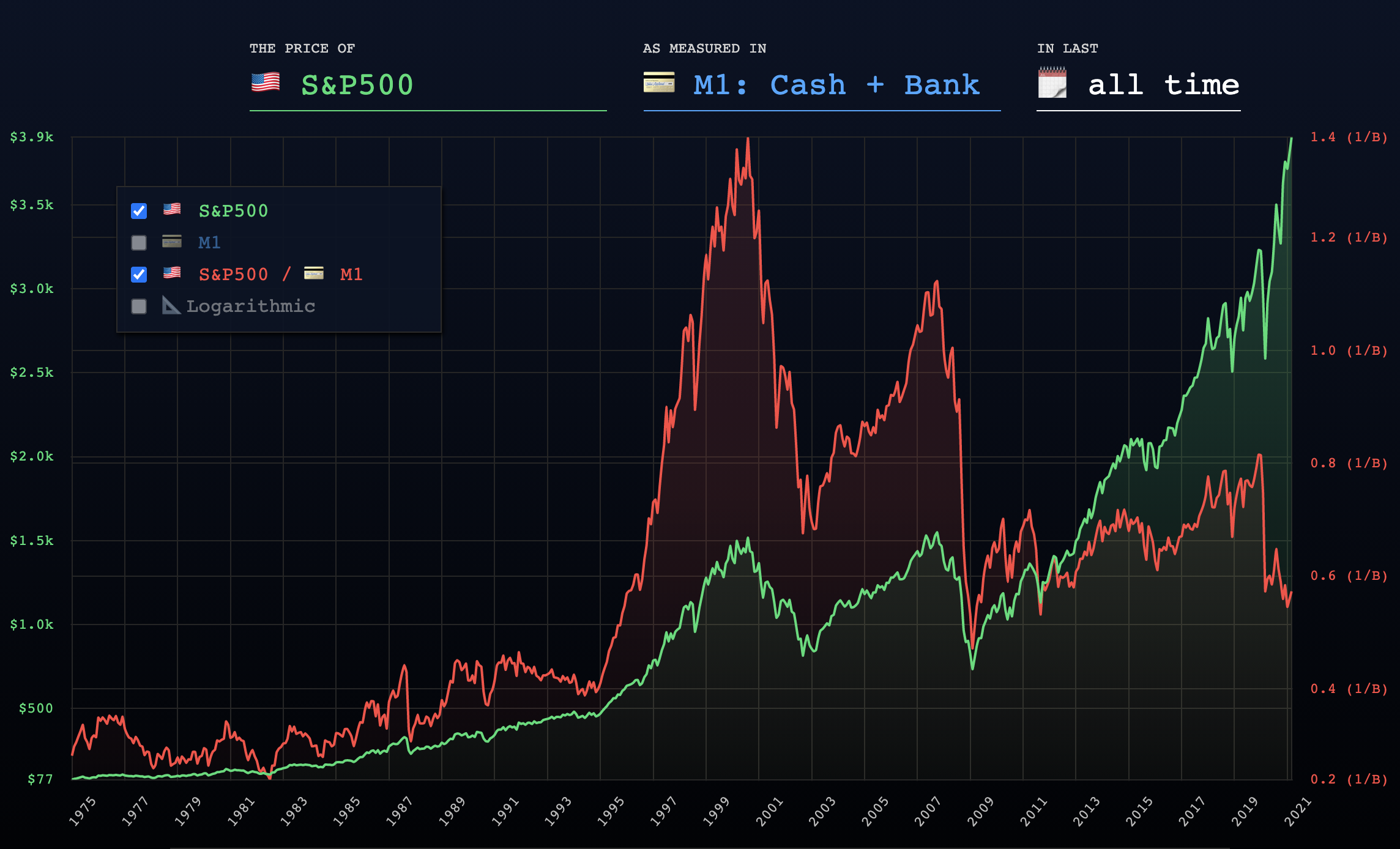
So where should we backup to? Well, Amazon has a huge server company that hosts a large part of the internet (e.g. Dropbox and major websites) called AWS. Most of you know this. And most of you might also know its service called S3. It’s a storage service many websites use to hold their static content (like images etc.). It’s redundant storage which means your files are probably not going to dissappear. It also has its own protocol s3:// that a lot of desktop and Linux apps support.
What’s great is that transferring to S3 is literally free. And storing it is only 3 cents per GB. My VPS is about 80 GB, so that’s $2.40/m for a redundant backup. Awesome, right?
Also their data center looks really cool. Who doesn’t want their files in here?

Let’s use S3 to set up a weekly backup.
Set up S3
If you’re not yet, let’s sign up to Amazon AWS here.
Then sign in to AWS and click S3 Scalable Storage in the Cloud.

We now want to create a bucket. A bucket is just a virtual server that stores your data.

You can pick a region, that’s where your server will be located. You can’t change that. You can create a new bucket and transfer everything to the other region but that DOES cost money. So make sure you pick the right region.
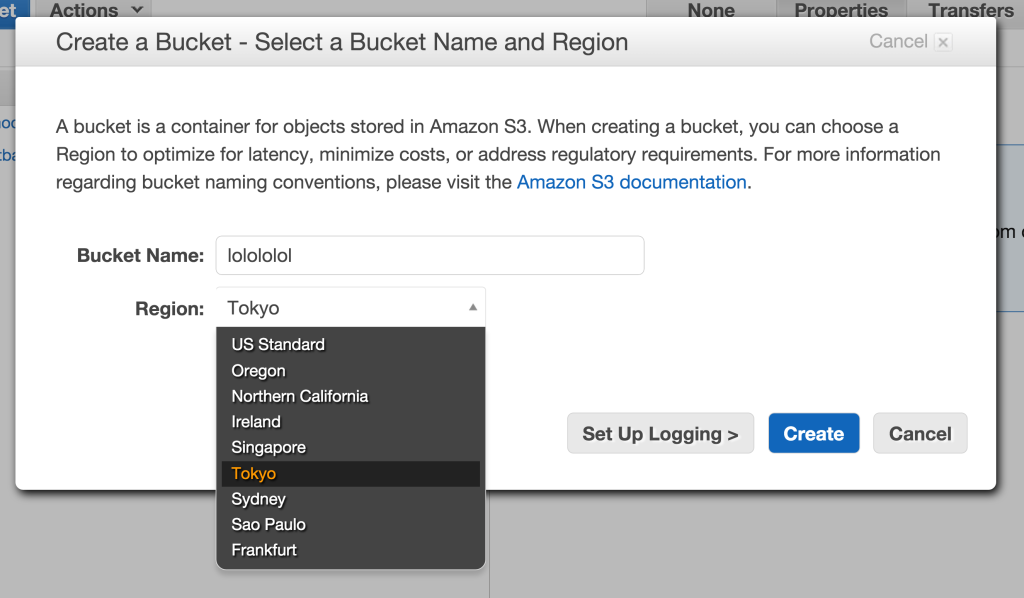
Give your bucket a name with ONLY alphanumeric characters. Make sure it’s kinda descriptive so you remember what the bucket is for.
My server is in London, so I picked United States as a region. Why? Well, I’m paranoid about data and what if a meteorite drops on the UK, where’s my data then, right?
After creating your S3 bucket, you need to set up your security credentials so you can let your VPS server access it.
Now you can do this super advanced writing your own security policies, but it’s just too hard for me. So instead I’m going to do something not so secure which is give your server access to your ENTIRE AWS account. This is super unsafe IF you have other stuff in that account. If you only have this bucket in there, it’s fine.
Click on your username (at the top-right) and select Security Credentials.
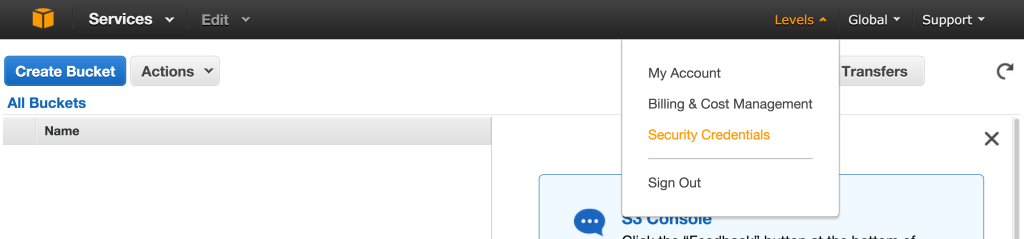
Then click “Delete your root access keys” and select “Manage Security Credentials”.
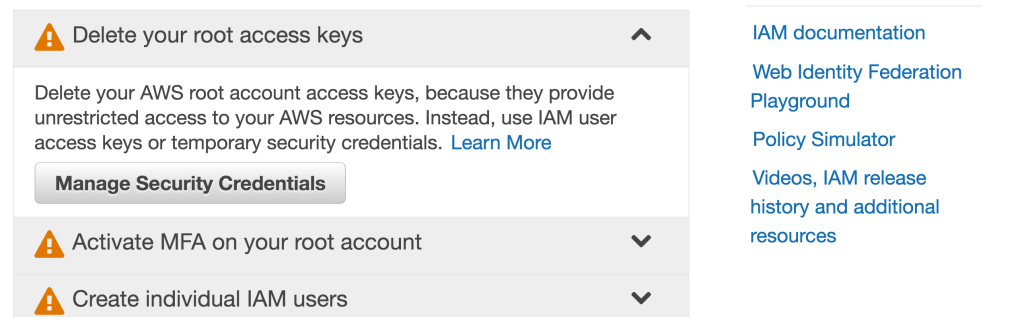
From there click “Access Keys” and select “Create New Access Key”.

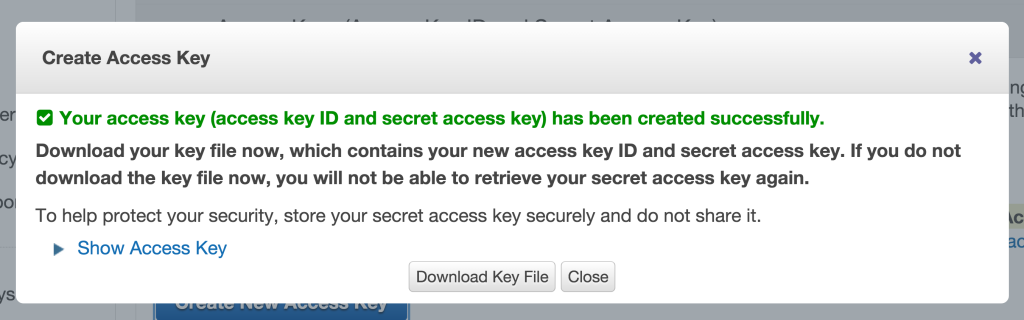
Your key is now created. This key is two-part, it contains an ID code and a secret code. You need both to access your bucket.
Click “Show Access Key” and save the Key and Secret code somewhere secure in a text file. You’re going to need this next.
Set up S3 on your VPS
Now it’s time to set up S3 on your VPS server.
I picked a few things from this tutorial by Kura. First we need to install s3cmd which is a Linux app that lets you transfer in and out of S3 super easily.
This code install s3cmd to your server and starts it configuration.
sudo wget -O- -q s3tools.org/repo/deb-all/stable/s3tools.key | sudo apt-key add - sudo wget s3tools.org/repo/deb-all/stable/s3tools.list -O /etc/apt/sources.list.d/s3tools.list sudo apt-get update && apt-get install s3cmd sudo s3cmd --configure
The questions in the configuration are pretty straightforward.
Enter your access key and secret key from your security credentials that you saved before.
At “Encryption password:”, it’s probably a good idea to specify a password with which your data will be encrypted when it transfers. You can generate a random one at random.org.
Just press ENTER at “Path to GPG program”, as you probably have GPG (an encryption program) installed already on your server at the default path. Press ENTER at “Use HTTPS protocol”, since it slows it down and you’re already encrypting it with GPG. I guess if you have super secure data turn this on instead. Press ENTER at “HTTP Proxy server name”, you probably don’t need that.
Then let the configuration app test the access and if it works continue. If not, check if your S3 credentials are set correctly.
Enter new values or accept defaults in brackets with Enter. Refer to user manual for detailed description of all options. Access key and Secret key are your identifiers for Amazon S3 Access Key: Secret Key: Encryption password is used to protect your files from reading by unauthorized persons while in transfer to S3 Encryption password: Path to GPG program [/usr/bin/gpg]: When using secure HTTPS protocol all communication with Amazon S3 servers is protected from 3rd party eavesdropping. This method is slower than plain HTTP and cannot be used if you are behind a proxy Use HTTPS protocol [No]: On some networks all internet access must go through a HTTP proxy. Try setting it here if you cannot conect to S3 directly HTTP Proxy server name: New settings: Access Key: Secret Key: Encryption password: Path to GPG program: /usr/bin/gpg Use HTTPS protocol: False HTTP Proxy server name: HTTP Proxy server port: 0 Test access with supplied credentials? [Y/n]
Now you need to connect to the bucket you created on S3:
s3cmd mb s3://nameofyours3bucket
If this works. Yay!
The s3cmd has a command called sync which syncs TO the remote server (not back locally, so don’t worry). Here’s an example (don’t run it!):
s3cmd sync --recursive --preserve /your-folder-name-to-backup s3://nameofyours3bucket
I’ve added –recursive to save all child directories and important –preserve which keeps all file attributes and permissions the same. VERY important if you’ll be transferring your backups back when the shit hits the fan.
You can now make a shell script (ending with .sh) that transfers the most important files of your server to S3 regularly. I thought about just doing
s3cmd sync --recursive --preserve /
but that also includes the ENTIRE Linux installation, I don’t know if that’s preferable as I only need the files that are important. The most important directories seemed to be /srv (that’s where I put my http files), /etc, /home and /var.
Also it’s useful to save a list of which apps you have installed on your server. You can do that with “dpkg –get-selections”. Then save that to “dpkg.list” and send that to S3 too.
The date functions logs the time so you have a better log of what’s happening later:
!/bin/sh echo 'Started' date +'%a %b %e %H:%M:%S %Z %Y' s3cmd sync --recursive --preserve /srv s3://nameofyours3bucket s3cmd sync --recursive --preserve /etc s3://nameofyours3bucket s3cmd sync --recursive --preserve /home s3://nameofyours3bucket s3cmd sync --recursive --preserve /var s3://nameofyours3bucket dpkg --get-selections > dpkg.list s3cmd sync --recursive --preserve dpkg.list s3://nameofyours3bucket date +'%a %b %e %H:%M:%S %Z %Y' echo 'Finished'
Save this file as backupToS3.sh. I’ve saved it in /srv on my server.
Test it by running it first and typing this in your shell:
sh backupToS3.sh
If it transfers well you can make it in to a regularly scheduled job by setting up a cron job by typing this in your shell:
sudo crontab -e
Then you’ll see a text editor with all your scheduled cron jobs. Add this line at the top:
@weekly /srv/backupToS3.sh > /srv/backupToS3.txt
This will run the backup weekly and save the output to a .txt log file that you can check to see if it ran correctly.
You can also use @daily and @monthly on most Linux installations. But if the backup takes a long time it might take longer than a day. So it’ll start while the other one is still running. Eek.
So that’s it! Mini-tip: s3cmd also runs on OSX, that means you can even backup your Mac to S3.
Conclusion
With an original copy on my server, a few Linode backups and now a redundant (!) S3 backup at Amazon, I feel a lot safer. Linode’s restore backup function is super smooth, but having an EXTRA backup present when THAT restore might go wrong is great.
Stay safe! Backup ALL THE THINGS!

P.S. I'm on 𝕏 too if you'd like to follow more of my stories. And I wrote a book called MAKE about building startups without funding. See a list of my stories or contact me.
To read every new post (including blogs from 𝕏) in full in your inbox, join 14,331 subscribers
You can unsubscribe easily and I promise to never spam you